La p�gina anterior nos ofreci� una introducci�n al API Java para Procesar XML (JAXP), y las tecnolog�as que directa o indirectamente proporcionan al desarrollador Java las tecnolog�as para poder procesar documentos XML. Ilustr� el uso de los diferentes APIs con algunos programas de ejemplo. Esta segunda p�gina se centra en el rendimiento relativo de estos APIs obtenidos ejecutando los programas de ejemplo presentados en la primera p�gina. Este tutorial concluye con una tecera p�gina en que ofreceremos trucos para mejorar el rendimiento de las aplicaciones basadas en XML desde un punto de vista program�tico y arquitectural.
El prop�sito de las pruebas presentadas en esta p�gina es principalmente ilustrar el rendimiento respectivo de las diferentes t�cnicas de procesamiento XML: SAX, DOM, XSLT, y el impacto de la valicaci�n contra un DTD o contra un Esquema XML. Tambi�n se comparan los rendimientos de las diferentes implementaciones del API: Xerces, Crimson, Xalan, Saxon, XSLTC, etc. cuando se ejecutan en diferentes entornos de ejecuci�n Java JDK 1.2 y JDK 1.3 . Los resultados presentados aqu� no pretenden cubrir todas las implementaciones del API disponibles hoy en d�a sino subrayar que la diferencia entre la facilidad de uso y el rendimiento de los modelos de procesamiento elegidos puede evitarse mediante la implementaci�n de un analizador, un constructor de documento o un motor de hoja de estilo subyacentes.
 �Metodolog�a
�Metodolog�a
Los programas de ejemplo presentados en la p�gina anterior demostraban el uso de los diferentes APIs disponibles. Para poder ser comparados, los hemos aplicado para resolver el mismo problema, y proporcionar id�ntica soluci�n. El problema se mantuvo simple para acomodar las diferentes capacidades de estas tecnologias y por lo tanto podr�a no tener la riqueza y potencia relevantes de otros m�s sofisticados como XSLT y XPath. En este respecto, las pruebas de rendimiento presentadas como micro-comparaciones.
Los programas de ejemplo estaban basados en los diferentes APIs para procesamiento de XML,
- SAX, Simple API for XML
- DOM, Document Object Model API from W3C
- XSLT, XML Style Sheet Language Transformations from W3C
- XPath, XML Path Language from W3C
- JDOM, "Java optimized" document object model API from jdom.org
aplicados al mismo conjunto de documentos para proporcioar exactamente la misma salida. Los documentos XML procesados usando estas t�cnicas diferentes est�n conforme a la misma Document Type Definition o XML Schema. Estos esquemas especifican la representaci�n de un conjunto de configuraciones de tableros de ajedrez:

Ilustraci�n 2.1: Una Configuraci�n de Tablero de Ajedrez.
En los esquemas, el n�mero de configuraciones de tableros es ilimitado, permitiendo que se defina cualquier n�mero de configuraciones dentro de un s�lo documento. Para poder medir el rendimiento de los diferentes programas de ejemplo, se han creado documentos con 10, 100, 200, 300, 400, 500, 1000, 2000, 3000, 4000 y 5000 configuraciones de tableros de ajedrez.
Los documentos XML conformes al Chessboards.dtd y al esquema Chessboards.xsd tienen id�ntica estructura y contenido, la �nica excepci�n es reemplazar la Declaraci�n de Tipo de Documento por una referencia al Esquema XML. Para la prueba que implica a los esquemas XML, s�lo se us� un documento con 100 configuraciones de tableros de ajedrez.
C�digo de ejemplo 1: Un documento XML conforme a la DTD (Chessboards-[10-5000].xml)
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE CHESSBOARDS SYSTEM "dtd/Chessboards.dtd"> <CHESSBOARDS> <CHESSBOARD> <WHITEPIECES> <KING><POSITION COLUMN="G" ROW="1" /></KING> <BISHOP><POSITION COLUMN="D" ROW="6" /></BISHOP> <ROOK><POSITION COLUMN="E" ROW="1" /></ROOK> <PAWN><POSITION COLUMN="A" ROW="4" /></PAWN> <PAWN><POSITION COLUMN="B" ROW="3" /></PAWN> <PAWN><POSITION COLUMN="C" ROW="2" /></PAWN> <PAWN><POSITION COLUMN="F" ROW="2" /></PAWN> <PAWN><POSITION COLUMN="G" ROW="2" /></PAWN> <PAWN><POSITION COLUMN="H" ROW="5" /></PAWN> </WHITEPIECES> <BLACKPIECES> <KING><POSITION COLUMN="B" ROW="6" /></KING> <QUEEN><POSITION COLUMN="A" ROW="7" /></QUEEN> <PAWN><POSITION COLUMN="A" ROW="5" /></PAWN> <PAWN><POSITION COLUMN="D" ROW="4" /></PAWN> </BLACKPIECES> </CHESSBOARD> <CHESSBOARD> ... </CHESSBOARD> </CHESSBOARDS>
Las diferentes implementaciones basadas en SAX, DOM, XSLT, XPath, etc, cuando se aplican sobre los mismos documentos de entrada, proporcionan la misma salida: una representaci�n en formato de texto de una configuraci�n de tablero de ajedrez.
C�digo de Ejemplo 2: Una representaci�n en formato de texto de una configuraci�n de tablero de ajedrez:
White king: G1 White bishop: D6 White rook: E1 White pawn: A4 White pawn: B3 White pawn: C2 White pawn: F2 White pawn: G2 White pawn: H5 Black king: B6 Black queen: A7 Black pawn: A5 Black pawn: D4
Todos los programas de ejemplo usan el API Java para Procesar XML (JAXP) para interactuar con las diferentes implementaciones subyacentes de los analizadores SAX, los constructores de documentos DOM y los motores de Transformaci�n XSL, y comparten una estructura com�n que pemite comparar sus respectivos rendimientos. Permiten el paso t�pico de usar JAXP, y adicionalmente incluyen dos bucles para procesar el mismo documento varias veces y en varias ejecuciones. Por cada ejecuci�n, se usa una factor�a para crear un analizador, una procesador de hoja de estilo, etc, que a su vez son usados para procesar un documento fuente XML varias veces. La validaci�n del documento fuente contra sus DTDs o Esquemas XML declarados podr�a ser especificada cuando se llama al programa y est� implementada configurando la factor�a a trav�s de su m�todo setValidating que crea un analizador con o sin validaci�n.
En el c�digo de ejemplo (ChessboardSAXPrinter.java) de abajo, despu�s de ejecutarse se saca el tiempo medio tardado en procesar un documento. Los tiempos del sistema y del usuario podr�an medirse lanzando la M�quina Virtual Java (JVM) con el comando ptime.
C�digo de Ejemplo 3: Ejemplo de la estructura com�n de los programas de ejemplo (ChessboardSAXPrinter.java)
import org.xml.sax.*;
import org.xml.sax.helpers.*;
import javax.xml.parsers.*;
public class ChessboardSAXPrinter {
private SAXParser parser;
public ChessboardSAXPrinter(boolean validating)
throws Exception {
SAXParserFactory factory
= SAXParserFactory.newInstance();
factory.setValidating(validating);
parser = factory.newSAXParser();
...
return;
}
public void print(String fileName, PrintStream out)
throws SAXException, IOException {
...
parser.parse(fileName, ...);
return;
}
public static void main(String[] args) {
...
for (int k = 0; k < r; k++) {
// r: number of runs
ChessboardSAXPrinter saxPrinter
= new ChessboardSAXPrinter(validating);
long time = System.currentTimeMillis();
for (int i = 0; i < n; i++) {
// n: number of document processed per run
saxPrinter.print(args[0], out);
}
// print out the average time (s)
// to process a document during the current run
System.err.print(
(((double) (System.currentTimeMillis()
- time)) / 1000 / n) + "\t");
}
...
}
}
Dependiendo del rendimiento probado, se realizan dos medidas diferentes:
- El tiempo medio tardado en procesar el documento, medido entre cada ejecuci�n del propio programa con dos llamadas al m�todo System currentTimeMillis. S�lo las �ltimas ejecuciones podr�an ser tenidas en cuenta para esta medida permitiendo que todas las clases sean cargadas en la M�quina Virtual para compilar y optimizar los byte codes antes de empezar la medida. Esta medida se utiliza normalmente para ilustrar las diferencias entre las M�quinas Virtuales y especialmente la mejora de optimizaci�n sobre el tiempo. Esta medida es senbile a factores externos, especialmente con la actividad del sistema no ralacionada con la prueba.
- La media del tiempo de sistema+usuario para procesar un documento, set� basada en la salida del comando ptime. La suma de los tiempos del sistema y del usuario para completar la ejecuci�n incluyendo la arrancada de la M�quina Virtual es medida y promediada por cada documento procesado. Esta medida es m�s fiable y se convierte en significante cuando el tiempo de arrancada es m�nimo comparado con la carga de trabajo preparada.
El fragmento de c�digo de un makefile (abajo) muestra que el programa fuente perf1 ChessboardSAXPrinter ser� ejecutado para todos los documentos fuente (../samples/Chessboards-{10, 100, 1000, 2000, 3000, 4000, 5000}.xml) seg�n se especifica en la variable SAMPLING y cada uno de esos documentos ser� procesado 10 veces (variable PROCESSINGS) por cada 10 ejecuciones (variable RUNS). Los tiempos de sistema y de usaurio ser�n medidos por el comando ptime y apropiadamente promediados y formateados por un script awk (variable FORMATTER). La variable OPTIONS permite pasar las propiedades seleccionadas a las implementaciones del analizador SAX, del constructor DOM o del motor XSLT para ser usadas. La propiedad XML.validation la usa el propio programa de ejemplo para activar o desactivar la validaci�n. La salida del program se redirige a /dev/null para minimizar el impacto de la I/O de disco en los resultados de rendimiento.
C�digo de Ejemplo 4: fragmento de c�digo de un makefile
SAMPLING=10 100 1000 2000 3000 4000 5000
MAXTIME=3000
RUNS=10
PROCESSINGS=10
TIMER=ptime
OPTIONS= \
-Djavax.xml.parsers.SAXParserFactory=\
org.apache.xerces.jaxp.SAXParserFactoryImpl \
-Djavax.xml.parsers.DocumentBuilderFactory=\
org.apache.xerces.jaxp.DocumentBuilderFactoryImpl \
-Djavax.xml.transformer.TransformerFactory=\
org.apache.xalan.processor.TransformerFactoryImpl
FORMATTER= \
/usr/xpg4/bin/awk -v runs=$${RUNS:=$(RUNS)} \
-v processings=$${PROCESSINGS:=$(PROCESSINGS)} ' \
BEGIN { \
count=0; m=split("1:60:3600", f, ":"); \
} { \
if ($$1=="sys" || $$1=="user") { \
n=split($$2, a, ":"); \
for (i = 1; i <= n; i++) { \
count += a[n - i + 1] * f[i]; \
} \
} \
} END {
printf ":%.4f", count / runs / processings; \
if (count > $(MAXTIME)) exit 1; \
}'
perf1:
echo "SAX/Validating (Xerces)\t\c"; \
for i in $(SAMPLING); \
do
$(TIMER) $(JAVA) -DXML.validation=true -Xms128m \
-Xmx128m -classpath $(CLASSPATH) $(OPTIONS)
ChessboardSAXPrinter ../samples/Chessboards-$$i.xml
/dev/null $(PROCESSINGS) $(RUNS) 2>&1 \
| tee -a $(LOGS) \
| $(FORMATTER) || break; \
done; \
echo
Para seleccionar la implementaci�n del analizador SAXL, del constructor DOM o del motor XSLT a probar, se pasan las siguientes propiedades JAXP a la JVM (variable OPTIONS en el ejemplo de arriba):
| API | Propiedad | Valor | Implementaci�n |
|---|---|---|---|
| SAX | javax.xml.parsers. SAXParserFactory |
org.apache.crimson.jaxp. SAXParserFactoryImpl |
Crimson |
| SAX | javax.xml.parsers. SAXParserFactory |
org.apache.xerces.jaxp. SAXParserFactoryImpl |
Xerces |
| DOM | javax.xml.parsers. DocumentBuilderFactory |
org.apache.crimson.jaxp. DocumentBuilderFactoryImpl |
Crimson |
| DOM | javax.xml.parsers. DocumentBuilderFactory |
org.apache.xerces.jaxp. DocumentBuilderFactoryImpl |
Xerces |
| XSLT | javax.xml.transformer. TransformerFactory |
org.apache.xalan.processor. TransformerFactoryImpl |
Xalan |
| XSLT | javax.xml.transformer. TransformerFactory |
com.icl.saxon. TransformerFactoryImpl |
Saxon |
| XSLT | javax.xml.transformer. TransformerFactory |
org.apache.xalan. xsltc.runtime. TransformerFactoryImpl |
Xalan-XSLTC |
�Configuraci�n
Cada programa de ejemplo se ha probado en diferentes configuraciones: con diferentes tama�os de documentos procesados conformes a sus DTD o a un esquema XML, con o sin validaci�n, con diferentes implementaciones de analizador o motor de hoja de estilo, y con diferentes versiones de la JVM
| Productos | y Versiones |
|---|---|
| WorkStation | Solaris Operating Environment (SPARC Platform Edition), Ultra-30 |
| Java Runtimes | JDK1.2.2_06, JDK1.3.1 |
| Analizadores XML,
Motores XSLT |
Xerces 1.3.1 y 1.4.4 (para XML Schemas)
Crimson 1.1 (incluido en JAXP 1.1) Xalan-Java 2.1 (incluyendo XSLTC) Saxon 6.3 JAXP 1.1 JDOM beta6 |
| Programas de Ejemplo/APIs | ChessboardSAXPrinter.java - SAX
ChessboardDOMPrinter.java - DOM XSLTTransformation.java y ChessboardPrinter.xsl - XSLT ChessboardXPathPrinter.java - XPath ChessboardJDOMPrinter.java - JDOM |
�Medidas de Rendimiento
�Comparar Rendimientos de SAX, DOM y XSLT
Esta prueba compara los rendimientos de SAX, DOM y XSLT cuando se aplican para procesar los documentos XML definidos anteriomente. Se han usado dos implementaciones de SAX y DOM: Xerces y Crimson.
Esta prueba midi� el tiempo para procesar documentos que describen 1000, 2000, 3000, 4000 y 5000 configuraciones de tableros de ajedrez. Cada documento ha sido procesado 10 veces en 10 ejecuciones. El tiempo medido fue sumado al tiempo del sistema y de usuario, y devuelto por el comando ptime, dividido por el n�mero total de documentos procesados.
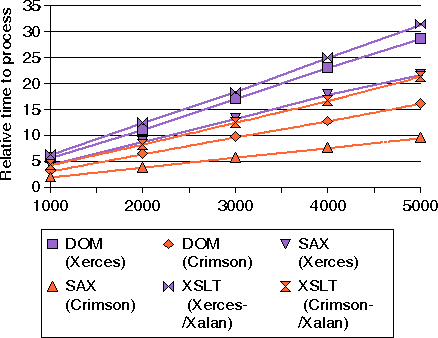
Ilustraci�n 2: tiempo para procesar diferentes tama�os de documentos XML usando SAX, DOM y XSLT con Crimson y Xerces (JDK 1.2)
An�lisis
Podemos hacer tres observaciones a partir de estas medidas:
- Como esperabamos, la clasificaci�n, del m�s r�pido al m�s lento, es: SAX, DOM, y XSLT. Esto puede explicarse por el hecho de que t�picamente un motor XSLT tiene que compilar la hoja de estilo y luego construir internamente el �rbol de salida antes de empezar las transformaciones. Podr�a usar un constructor DOM para hacer esto. El propio constructor DOM podr�a usar un analizador SAX para analizar tanto el documento de entrada como la hoja de estilo. Si juntamos est�s t�ncicas, a�aden m�s funcionalidad, facilidad de uso y de mentenimiento, pero penalizan m�s el rendimiento.
- Crimson rinde mejor que Xerces. Crimson es una implementaci�n correcta de un analizador XML y tiene un peque�o tama�o 200KB (su tama�o de fichero jar) mientras que Xerces es m�s sofisticado e incluye muchas caracter�sticas adicionales como soporte de Esquemas XML. Xerces tambi�n viene con soporte DOMs de WML y HTML lo que incrementa significativamente el tama�o de su fichero jar hasta 1.5MB. La organizaci�n Apache est� re-construyendo Xerces y mejorando en el rendimiento en Xerces2.
- El tiempo de proceso de un documento se incrementa linearmente con el tama�o del documento. La linearidad del rendimiento demuestra que el test no expuso al m�ximo ning�n recurso del sistema, especialmente la memoria. Teniendo en cuenta esta lineraridad, para la mayor�a de los siguientes gr�ficos s�lo presentaremos los resultados de procesar el documento 1000-Chessboard XML de esta forma:
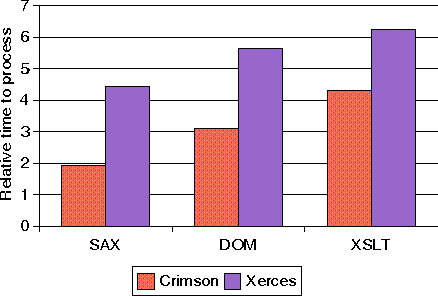
Ilustraci�n 3: Tiempo para procesar documentos XML 1000-Chessboard XML usando SAX, DOM y XSLT con Crimson y Xerces (JDK 1.2)
�Comparar los Rendimientos de XSLT y XSLTC
Esta segunda prueba compara el rendimiento de motores XSLT normales y del motor XSLTC que compila las hojas de estilo en byte codes Java. XSLTC es ahora parte de Xalan y puede invocarse a trav�s del JAXP. No se necesitaron modificaciones en el programa de ejemplo para usar XSLTC.
Esta prueba midi� el tiempo para procesar documentos que describen 1000, 2000, 3000, 4000 y 5000 configuraciones de tableros de ajedrez (aunque aqu� s�lo presentemos el resultado de los documentos de 1000 configuraciones). Cada documento ha sido procesado 10 veces en 10 ejecuciones. El tiempo medido fue sumado al tiempo del sistema y de usuario, y devuelto por el comando ptime, dividido por el n�mero total de documentos procesados.
Medidas
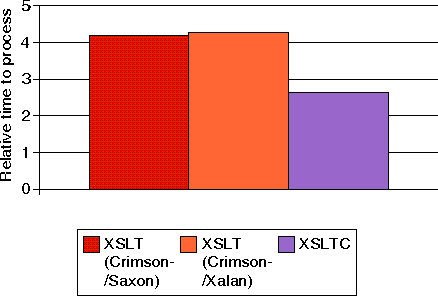
Ilustraci�n 4: Tiempo de procesar documentos XML de 1000-Chessboard usando XSLT y XSLTC (JDK 1.2)
An�lisis
Esta prueba mostr� que Xalan y Saxon rinden pr�cticamente lo mismo y que compilar las hojas de estilo en byte codes Java podr�a mejorar el rendimiento hasta en un 40% cuando se compara con las implementaciones cl�sicas como Xalan o Saxon sobre Crimson. Compar�ndolo con las pruebas anteriores, las hojas de estilo compiladas podr�an dar mejor rendimiento que DOM y muy cercano a SAX
�Comparar Rendimiento con Validaci�n y sin Validaci�n
Ahora comparamos los rendimientos de SAX y DOM con y sin validaci�n. Usando las implementaciones SAX y DOM de Crimson y Xerces. Lo que se pretende aqu� es medir el impacto de la validaci�n en el tiempo de proceso. Para las especificaciones XML, un analizador sin validaci�n no se requiere que lea las entidades externas (incluyendo una DTD externa); por lo tanto las entidades externas referenciadas en el documento podr�an no ser expandidas y los atributos podr�an no tener sustituidos sus valores por defecto. As�, la informaci�n pasada a la aplicaci�n llamante podr�a no ser equivalente cuando se usa un analizador con o sin validaci�n. En el contexto de este documento, s�lo consideramos los analizadores que incluso cuando son sin validaci�n, cargan y analizan la DTD y las entidades referenciadas en el documento. Este permite, por ejemplo, que las entidades sean susituidas, que los valores de atributos sean normalizados y sus valores por defecto apropiadamente sustituidos, por eso que la aplicaci�n se puede ejecutar sin ningun cambio cuando cambiamos de validaci�n a sin validaci�n el documento de entrada.
Esta prueba midi� el tiempo para procesar documentos que describen 1000, 2000, 3000, 4000 y 5000 configuraciones de tableros de ajedrez (aunque aqu� s�lo presentemos el resultado de los documentos de 1000 configuraciones). Cada documento ha sido procesado 10 veces en 10 ejecuciones. El tiempo medido fue sumado al tiempo del sistema y de usuario, y devuelto por el comando ptime, dividido por el n�mero total de documentos procesados.
Medidas
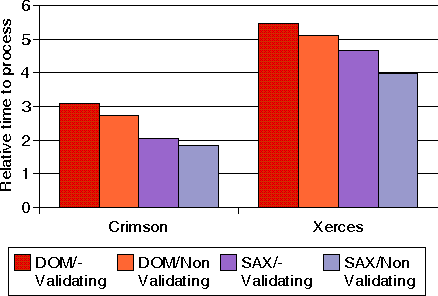
ILustraci�n 5: Tiempo para procesar un documento XML de 1000 configuraciones de tablero de ajedrez usando las implementaciones de DOM y SAX de Crimson y Xerces con y sin validaci�n.
An�lisis
SAX rinde mejor que DOM y la validaci�n de los documentos XML de entrada contra sus DTDs incurre en una sobrecarga de hasta el 12% en el caso de la implementaci�n SAX de Xerces. Con la excepci�n de la implementaci�n SAX de Xerces, el coste de la validaci�n es independiente del API utilizado. La validaci�n se realiza internamente en el analizador. Si un constructor DOM se implementa sobre un analizador DocumentHandler personalizado (ContentHandler en SAX 2), entonces la diferencia entre DOM y SAX se puede tener en cuenta para la construcci�n del �rbol DOM desde los eventos SAX disparados por el analizador.
�Comparar Rendimientos de APIs Alternativos (JDOM, Xpath, YAXA)
Esta prueba compara los rendimientos de DOM con JDOM y XPath. El programa de ejemplo JDOM usa un SAXBuilder para analizar el documento fuente XML en memoria. Pasa a trav�s del documento JDOM resultante y saca el resultado en formato texto. El programa de ejemplo XPath usa el API DOM para analizar y cargar un documento XML en memoria. Luego eval�a expresiones XPath para localizar elementos a ser procesados y saca el resultado en formato texto.
Adicionalmente, esta prueba compara YAXA con SAX y DOM. YAXA es un API experimental que funciona sobre SAX y anade el cl�sico paradigma Java Event/Source/Listener. El programa de ejemplo YAXA usa un DefaultHandler de SAX2 personalizado para registrar oyentes de eventos que capturan los eventos disparados por el analizador SAX subyacente. YAXA tambi�n proprociona un editor de streams de eventos basado en el modelo anterior que edita directamente el flujo de eventos disparado por el analizador SAX. El programa de ejemplo YAXA-SE usa este editor de streams para aplicar un script de edici�n al flujo de eventos y genera la misma salida que los otros proramas. El editor de streams de eventos estaba inspirado en el comando sed de UNIX.
Esta prueba midi� el tiempo para procesar documentos que describen 1000, 2000, 3000, 4000 y 5000 configuraciones de tableros de ajedrez (aunque aqu� s�lo presentemos el resultado de los documentos de 1000 configuraciones). Cada documento ha sido procesado 10 veces en 60 ejecuciones. El tiempo medido fue sumado al tiempo del sistema y de usuario, y devuelto por el comando ptime, dividido por el n�mero total de documentos procesados.
Medidas
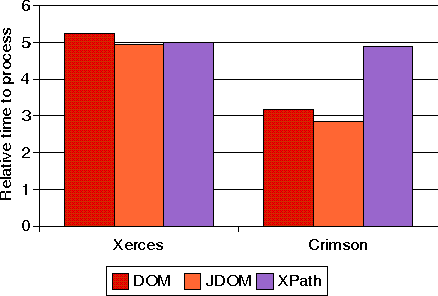
Ilustraci�n 6: Tiempo para procesar un documento XML con 1000 configuraciones de tableros de ajedrez con DOM, JDOM y XPath, usando Crimson y Xerces con validaci�n (JDK 1.2)
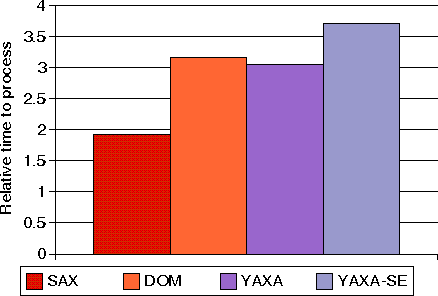
Ilustraci�n 7: Tiempo para procesar un documento XML con 1000 configuraciones de tableros de ajedrez con SAX, DOM, YAXA y YAXA-SE (editor de streams de eventos), usando Crimson con validaci�n (JDK 1.2)
An�lisis
JDOM es ligeramente m�s r�pido que DOM (alrededor de un 10%) usando la misma implementaci�n de analizador subyacente. Por otro lado XPath rinde de forma casi id�ntica, independientemente de la implementaci�n del analizador subyacente. Esto es debido al hecho de que la mayor�a del tiempo se va en localizar los elementos relevantes para ser procesados con la expresiones XPath. Como hemos usado la misma implementaci�n de XPath (de Xalan), el tiempo de proceso total es el mismo.
El rendimiento de YAXA es un poco mejor que el de DOM. Como los elementos a procesar constituyen el 90% de todo el documento, termina la creaci�n de eventos de la misma forma que DOM crea objetos nodo. Tambi�n sigue la pista del contexto actual con una pila que es casi equivalente a construiir el �rbol de modelo del documento. Por otro lado, con un simple pero comparable (en el ejemplo dado) mecanismo de correspondencia de patr�n, YAXA y el editor de streams de YAXA rinden mejor que XPath y XSLT para esta tarea sencilla.
�Comparar Diferentes Versiones de la JVM
Esta prueba compara el rendimiento de tres diferentes implementaciones/configuraciones del entorno de ejecuci�n Java, JDK 1.2, JDK 1.3 servidor, y JDK 1.3 cliente. Se usaron para procesar los documentos XML definidos anteriormente con dos diferentes implementaciones de SAX y DOM (Xerces y Crimson).
Esta prueba midi� el tiempo para procesar documentos que describen 1000, 2000, 3000, 4000 y 5000 configuraciones de tableros de ajedrez (aunque aqu� s�lo presentemos el resultado de los documentos de 1000 configuraciones). Cada documento ha sido procesado 10 veces en 60 ejecuciones. El tiempo medido fue sumado al tiempo del sistema y de usuario, y devuelto por el comando ptime, dividido por el n�mero total de documentos procesados.
Medidas
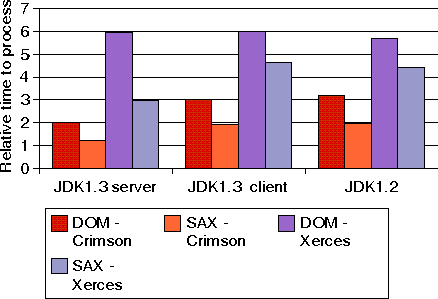
Ilustraci�n 8: Tiempo para procesar un documento XML con 1000 configuraciones de tableros de ajedrez usando SAX, DOM, con Crimson y Xerces sobre JDK 1.2, JDK 1.3 Client, y JDK 1.3 Server.
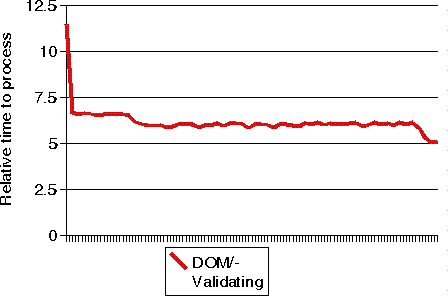
Ilustraci�n 9: El entorno de ejecuci�n JDK 1.3 Server mejor� sobre las 60 ejecuciones del programa de ejemplo DOM sobre Xerces. Una sensible optimizaci�n se realiz� al final de la prueba que no pudo mostarse en el gr�fico anterior
An�lisis
Los entornos JDK 1.2 y JDK 1.3 Client rinden de forma similar. Con la excepci�n del programa DOM que usa Xerces, el entorno JDK 1.3 Server es capaz de mejorar el rendimiento de JDK 1.2 entre un 33 y un 38%. Por otro lado, para los programas de ejemplo DOM usando Xerces, el rendimiento baj� un 5%, pero como se ve en la curva, al final del periodo de ejecuci�n el entorno JDK 1.3 Server fue capaz de optrimizarlo y ganar un 17% (de 6 a 5).
�Comparar el Rendimiento de los M�todos de Acceso DOM
El API DOM ofrece diferentes m�todos para acceder a un enlemento de un documento de entrada:
- Por nombre (usando getElementsByTagName), todos los elementos con un nombre de etiqueta dado ser�n devueltos en el orden en que sean encontrados en un orden pr�vio desde el nodo documento o elemento actual.
- Bajando por la estructura del �rbol (usando getChildNodes), se devolveran todos los hijos inmediatos del nodo documento o elemento actual.
El primer m�todo es m�s costoso porque se tiene que atravesar totalmente el sub-arbol por cada llamada al m�todo getElementsByTagName, poro podr�a requerir menos conocimiento de la estructura del �rbol ya que se hace una b�squeda exhaustiva. La b�squeda de diferentes nombres de elementos podr�a requerir atravesar el �rbol varias veces. El segundo m�todo es menos costoso porque el atravesamiento del �rbol est� controlado: s�lo las partes relevantes del sub-�rbol podr�an ser atravesadas y podr�a serlo s�lo una vez; pero por otro lado, requiere un conocimiento m�s profundo de la estructura del documento.
Hasta ahora, las pruebas DOM s�lo utilizaron el segundo m�todo. Esta prubea mide la diferencia entre estas dos implementaciones de DOM.

Ilustraci�n 10: Tiempo para procesar diferentes tama�os de documentos XML usando diferentes m�todos del API DOM y diferentes implementaciones (JDK 1.2)
An�lisis
Como esperabamos, el m�todo que trata con el m�todo getElementsByTagName es m�s lento que los otros. Pero dependiendo de la implementaci�n (espec�ficamente la implementaci�n del algoritmo que pasa a trav�s del �rbol), la diferencia podr�a ser peque�a (Xerces) o dram�ticamente mayor/explosiva (Crimson).
�Comparar el Rendimiento de la Validaci�n de DTD y de Esquema XML
Esta prueba compara el rendimiento de las validaciones contra DTDs y Esquemas XML. Usa la implementaci�n SAX de Xerces (la �nica de las dos implementaciones que soporta Esquemas XML).
Esta prueba midi� el tiempo para procesar documentos que describen 1000, 2000, 3000, 4000 y 5000 configuraciones de tableros de ajedrez (aunque aqu� s�lo presentemos el resultado de los documentos de 1000 configuraciones). Cada documento ha sido procesado 10 veces en 10 ejecuciones. El tiempo medido fue sumado al tiempo del sistema y de usuario, y devuelto por el comando ptime, dividido por el n�mero total de documentos procesados.
Medidas
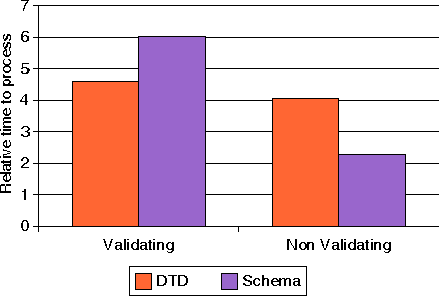
Ilustraci�n 11: Tiempo para procesar un documento XML con 1000 configuraciones de tableros de ajedrez usando la implementaci�n SAX de Xerces con validaci�n contra un DTD y un esquema XML (usando Xerces 1.4.4).
An�lisis
Con Xerces, la validaci�n contra un Esquema XML es m�s costosa que contra un DTD equivalente. Cuando no se realiza validaci�n, usar un Esquema XML parece ser m�s r�pido que usar el DTD. Esto es debido al hecho de que en esta implementaci�n particular de Xerces (1.4.4), el esquema XML referenciado en el documento de entrada ni siquiera es le�do (como hemos revelado monitorizando las llamadas al m�todo EntityResolver). El ejemplar del documento del Esquema XML es por lo tanto tratado como un documento sin DTD (ya que no hay incluso una Declaraci�n de Tipo de Documento - DOCTYPE).
Cuando se ejecuta la comparaci�n con una versi�n m�s reciente de Xerces (2.0b4), cuando no se realiza validaci�n, usar el esquema XML es m�s lento que usar la DTD, casi haciendo la imagen inversa de los resultados obtenidos cuando se valida. En este ejemplar particular, la monitorizaci�n de las llamadas a EntityResolver mostr� que el Esquema XML era cargado y analizado efectivamente. Incidentalmente, tambi�n observamos una sensible mejora del rendimiento con esta nueva versi�n de Xerces.
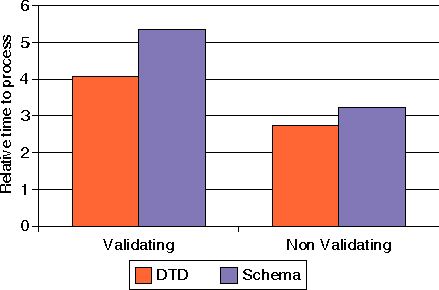
Ilustraci�n 12: Tiempo para procesar un documento XML con 1000 configuraciones de tableros de ajedrez usando la implementaci�n SAX de Xerces con validaci�n contra un DTD y un esquema XML (usando Xerces 2.0b4).
�Conclusi�n
En esta p�gina, hemos probado los diferentes programas de ejemplo presentados en la p�gina anterior y hemos analizado sus respectivos rendimientos cuando se ejecutan en diferentes configuraciones: con diferentes tama�os de documentos procesados, conformes a una DTD o a un Esquema XML, con o sin validaci�n, con diferentes implementaciones de analizadores o motores de hojas de estilos subyacentes y con diferentes versiones de la JVM. Teniendo en cuenta los resultados presentados, la siguiente p�gina intentar� mostrarnos algunos trucos para mejorar el rendimiento de las aplicaciones basadas en XML desde un punto de vista program�tico y arquitectural.