Para ampliar un negocio, se necesita que la informaci�n sea comprensible. Para muchas compa��as, esto significa un gran data warehouse que muestre, junto a los datos no filtrados y dispersos, nuevas formas creativas de presentaci�n.
Las herramientas para capturar y explorar los datos al detalle evolucionan, as� como nuestra capacidad para encontrar las formas de explotar los datos recolectados.
En los �ltimos 10 a�os se han combinado dos factores para ayudar a la difusi�n de los data warehouses. Ellos son:
- Se ha reconocido los beneficios del procesamiento anal�tico en l�nea (On Line Analytical Processing - OLAP), m�s all� de las �reas tradicionales de marketing y finanzas.
Las organizaciones saben que los conocimientos inmersos en las masas de datos que rutinariamente recogen sobre sus clientes, productos, operaciones y actividades comerciales, contribuyen a reducir los costos de operaci�n y aumentar las rentas, por no mencionar que es m�s f�cil la toma de decisiones estrat�gicas.
- El crecimiento de la computaci�n cliente/servidor, ha creado servidores de hardware y software m�s poderosos y sofisticados que nunca. Los servidores de hoy compiten con las mainframes de ayer y ofrecen arquitecturas de memoria tecnol�gicamente superiores, procesadores de alta velocidad y capacidades de almacenamiento masivas.
Al mismo tiempo, los Sistemas de Gesti�n de Base de Datos (Data Base Management Systems - DBMS(s)) modernos, proporcionan mayor soporte para las estructuras de datos complejas.
De esta renovaci�n de hardware y software surgen los data warehouses multiterabyte que ahora se ve en ambientes de cliente/servidor.
 �Consideraciones Previas al Desarrollo de un Data Warehouse
�Consideraciones Previas al Desarrollo de un Data Warehouse
Hay muchas maneras para desarrollar data warehouses como tantas organizaciones existen. Sin embargo, hay un n�mero de dimensiones diferentes que necesitan ser consideradas:
- Alcance de un data warehouse
- Redundancia de datos
- Tipo de usuario final
La Figura N� 15 muestra un esquema bidimensional para analizar las opciones b�sicas. La dimensi�n horizontal indica el alcance del dep�sito y la vertical muestra la cantidad de datos redundantes que deben almacenarse y mantenerse.
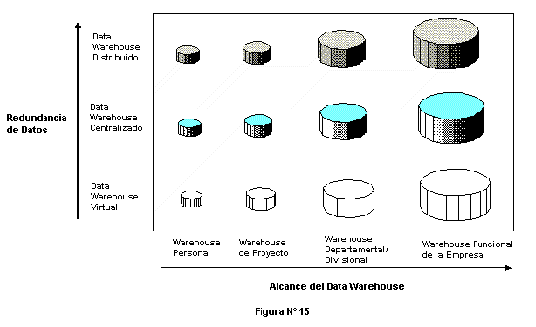
�Alcance de un Data Warehouse
El alcance de un data warehouse puede ser tan amplio como toda la informaci�n estrat�gica de la empresa desde su inicio, o puede ser tan limitado como un data warehouse personal para un solo gerente durante un a�o.
En la pr�ctica, en la amplitud del alcance, el mayor valor del data warehouse es para la empresa y lo m�s caro y consumidor de tiempo es crear y mantenerlo. Como consecuencia de ello, la mayor�a de las organizaciones comienzan con data warehouses funcionales, departamentales o divisionales y luego los expanden como usuarios que proveen retroalimentaci�n.
�Redundancia de Datos
Hay tres niveles esenciales de redundancia de datos que las empresas deber�an considerar en sus opciones de data warehouse:
- Data warehouses "virtual" o "Point to Point"
- Data warehouses "centrales"
- Data warehouses "distribuidos"
No se puede pensar en un �nico enfoque. Cada opci�n adapta un conjunto espec�fico de requerimientos y una buena estrategia de almacenamiento de datos, lo constituye la inclusi�n de las tres opciones.
- Data Warehouses "Virtual" o "Point to Point"
-
Una estrategia de data warehouses virtual, significa que los usuarios finales pueden acceder a bases de datos operacionales directamente, usando cualquier herramienta que posibilite "la red de acceso de datos".
Este enfoque provee flexibilidad as� como tambi�n la cantidad m�nima de datos redundantes que deben cargarse y mantenerse. Adem�s, se pueden colocar las cargas de consulta no planificadas m�s grandes, sobre sistemas operacionales.
Como se ver�, el almacenamiento virtual es, frecuentemente, una estrategia inicial, en organizaciones donde hay una amplia (pero en su mayor parte indefinida) necesidad de conseguir la data operacional, desde una clase relativamente grande de usuarios finales y donde la frecuencia probable de pedidos es baja.
Los dep�sitos virtuales de datos proveen un punto de partida para que las organizaciones determinen qu� usuarios finales est�n buscando realmente.
- Data Warehouses "Centrales"
-
El concepto de data warehouses centrales es el concepto inicial que se tiene del data warehouse. Es una �nica base de datos f�sica, que contiene todos los datos para un �rea funcional espec�fica, departamento, divisi�n o empresa.
Los data warehouses centrales se seleccionan por lo general donde hay una necesidad com�n de los datos inform�ticos y un n�mero grande de usuarios finales ya conectados a una red o computadora central. Pueden contener datos para cualquier per�odo espec�fico de tiempo. Com�nmente, contienen datos de sistemas operacionales m�ltiples.
Los data warehouses centrales son reales. Los datos almacenados en el data warehouse son accesibles desde un lugar y deben cargarse y mantenerse sobre una base regular. Normalmente se construyen alrededor de RDBMS avanzados o, en alguna forma, de servidor de base de datos inform�tico multidimensional.
- Data Warehouses Distribuidos
-
Los data warehouses distribuidos son aquellos en los cuales ciertos componentes del dep�sito se distribuyen a trav�s de un n�mero de bases de datos f�sicas diferentes.
Cada vez m�s, las organizaciones grandes est�n tomando decisiones a niveles m�s inferiores de la organizaci�n y a la vez, llevando los datos que se necesitan para la toma de decisiones a la red de �rea local (Local Area Network - LAN) o computadora local que sirve al que toma decisiones.
Los data warehouses distribuidos com�nmente involucran la mayor�a de los datos redundantes y como consecuencia de ello, se tienen procesos de actualizaci�n y carga m�s complejos.
�Tipo de Usuario Final
De la misma forma que hay una gran cantidad de maneras para organizar un data warehouse, es importante notar que tambi�n hay una gama cada vez m�s amplia de usuarios finales.
En general, se puede considerar tres grandes categor�as:
- Ejecutivos y gerentes
- "Power users" o "Buzo de Informaci�n" (analistas financieros y de negocios, ingenieros, etc.)
- Usuarios de soporte (de oficina, administrativos, etc.).
Cada una de estas categor�as diferentes de usuario tienen su propio conjunto de requerimientos para los datos, acceso, flexibilidad y facilidad de uso.
�Elementos Claves para el Desarrollo de un Data Warehouse
Los data warehouses exitosos comienzan cuando se escogen e integran satisfactoriamente tres elementos claves.
Un data warehouse est� integrado por un servidor de hardware y los DBMS que conforman el dep�sito. Del lado del hardware, se debe combinar la configuraci�n de plataformas de los servidores, mientras se decide c�mo aprovechar los saltos casi constantes de la potencia del procesador. Del lado del software, la complejidad y el alto costo de los DBMSes fuerzan a tomar decisiones dr�sticas y balances comparativos inevitables, con respecto a la integraci�n, requerimientos de soporte, desempe�o, eficiencia y confiabilidad.
Si se escoge incorrectamente, el data warehouse se convierte en una gran empresa con problemas dif�ciles de trabajar en su entorno, costoso para arreglar y dif�cil de justificar.
Para conseguir que la implementaci�n del dep�sito tenga un inicio exitoso, se necesita enfocar hacia tres bloques claves de construcci�n:
- Arquitectura total del dep�sito
- Arquitecturas del servidor
- Sistemas de Gesti�n de Base de Datos
A continuaci�n se presentan algunas recomendaciones para tomar las correctas elecciones para su empresa.
�Dise�o de la Arquitectura
Arquitectura del Dep�sito
El desarrollo del data warehouse comienza con la estructura l�gica y f�sica de la base de datos del dep�sito m�s los servicios requeridos para operar y mantenerlo. Esta elecci�n conduce a la selecci�n de otros dos �tems fundamentales: el servidor de hardware y el DBMS.
La plataforma f�sica puede centralizarse en una sola ubicaci�n o distribuirse regional, nacional o internacionalmente. A continuaci�n se dan las siguientes alternativas de arquitectura:
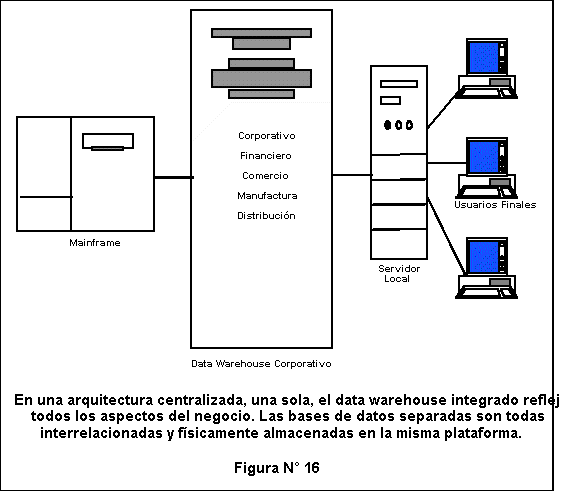
- Un plan para almacenar los datos de su compa��a, que podr�a obtenerse desde fuentes m�ltiples internas y externas, es consolidar la base de datos en un data warehouse integrado. El enfoque consolidado proporciona eficiencia tanto en la potencia de procesamiento como en los costos de soporte. (Ver Figura N� 16).
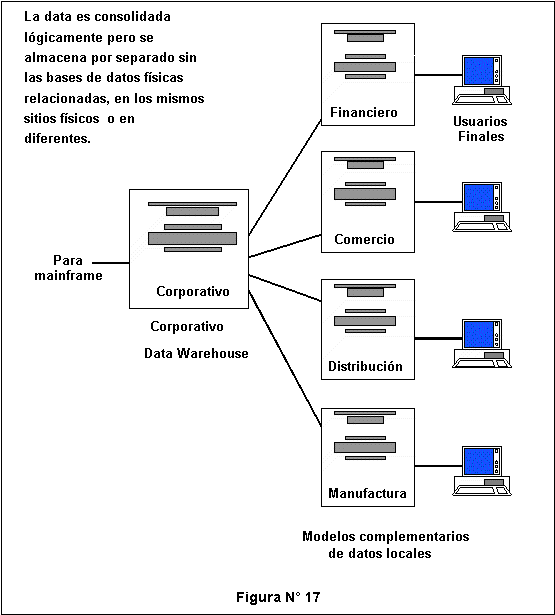
- La arquitectura global distribuye informaci�n por funci�n, con datos financieros sobre un servidor en un sitio, los datos de comercializaci�n en otro y los datos de fabricaci�n en un tercer lugar. (Ver Figura N� 17)
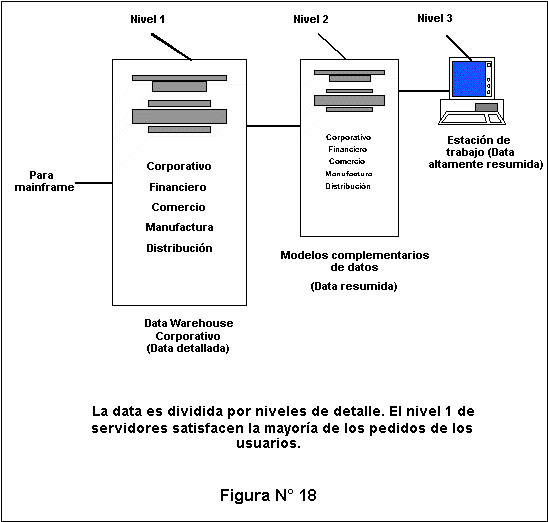
- Una arquitectura por niveles almacena datos altamente resumidos sobre una estaci�n de trabajo del usuario, con res�menes m�s detallados en un segundo servidor y la informaci�n m�s detallada en un tercero.
La estaci�n de trabajo del primer nivel maneja la mayor�a de los pedidos para los datos, con pocos pedidos que pasan sucesivamente a los niveles 2 y 3 para la resoluci�n.
Las computadoras en el primer nivel pueden optimizarse para usuarios de carga pesada y volumen bajo de datos, mientras que los servidores de los otros niveles son m�s adecuados para procesar los vol�menes pesados de datos, pero cargas m�s livianas de usuario. (Ver figura N� 18).
Arquitectura del servidor
Al decidir sobre una estructura de dep�sito distribuida o centralizada, tambi�n se necesita considerar los servidores que retendr�n y entregar�n los datos. El tama�o de su implementaci�n (y las necesidades de su empresa para escalabilidad, disponibilidad y gesti�n de sistemas) influir� en la elecci�n de la arquitectura del servidor.
- Servidores de un solo procesador
Los servidores de un s�lo procesador son los m�s f�ciles de administrar, pero ofrecen limitada potencia de procesamiento y escalabilidad. Adem�s, un servidor s�lo presenta un �nico punto de falla, limitando la disponibilidad garantizada del dep�sito.
Se puede ampliar un solo servidor de redes mediante arquitecturas distribuidas que hacen uso de subproductos, tales como Ambientes de Computaci�n Distribuida (Distributed Computing Environment - DCE) o Arquitectura Broker de Objeto Com�n (Common Objects Request Broker Architecture - CORBA), para distribuir el tr�fico a trav�s de servidores m�ltiples.
Estas arquitecturas aumentan tambi�n la disponibilidad, debido a que las operaciones pueden cambiarse al servidor de copia de seguridad si un servidor falla, pero la gesti�n de sistemas es m�s compleja.
- Multiprocesamiento sim�trico
Las m�quinas de multiprocesamiento sim�trico (Symmetric MultiProcessing - SMP) aumentan mediante la adici�n de procesadores que comparten la memoria interna de los servidores y los dispositivos de almacenamiento de disco.
Se puede adquirir la mayor�a de SMP en configuraciones m�nimas (es decir, con dos procesadores) y levantar cuando es necesario, justificando el crecimiento con las necesidades de procesamiento. La escalabilidad de una m�quina SMP alcanza su l�mite en el n�mero m�ximo de procesadores soportados por los mecanismos de conexi�n (es decir, el backplane y bus compartido).
- Procesamiento en paralelo masivo
Una m�quina de procesamiento en paralelo masivo (Massively Parallel Processing - MPP), conecta un conjunto de procesadores por medio de un enlace de banda ancha y de alta velocidad. Cada nodo es un servidor, completo con su propio procesador (posiblemente SMP) y memoria interna. Para optimizar una arquitectura MPP, las aplicaciones deben ser "paralelizadas" es decir, dise�adas para operar por separado, en partes paralelas.
Esta arquitectura es ideal para la b�squeda de grandes bases de datos. Sin embargo, el DBMS que se selecciona debe ser uno que ofrezca una versi�n paralela. Y a�n entonces, se requiere un dise�o y afinamiento esenciales para obtener una �ptima distribuci�n de los datos y prevenir "hot spots" o "data skew" (donde una cantidad desproporcionada del procesamiento es cambiada a un nodo de procesamiento, debido a la partici�n de los datos bajo su control).
- Acceso de memoria no uniforme
La dificultad de mover aplicaciones y los DBMS a agrupaciones o ambientes realmente paralelos ha conducido a nuevas y recientes arquitecturas, tales como el acceso de memoria no uniforme (Non Uniform Memory Access - NUMA).
NUMA crea una sola gran m�quina SMP al conectar m�ltiples nodos SMP en un solo (aunque f�sicamente distribuida) banco de memoria y un ejemplo �nico de OS. NUMA facilita el enfoque SMP para obtener los beneficios de performance de las grandes m�quinas MPP (con 32 o m�s procesadores), mientras se mantiene las ventajas de gesti�n y simplicidad de un ambiente SMP est�ndar.
Lo m�s importante de todo, es que existen DBMS y aplicaciones que pueden moverse desde un solo procesador o plataforma SMP a NUMA, sin modificaciones.
�Sistemas de Gesti�n de Bases de Datos
Los data warehouses (conjuntamente con los sistemas de soporte de decisi�n [Decision Support Systems - DSS] y las aplicaciones cliente/servidor), fueron los primeros �xitos para el DBMS relacional (Relational Data Base Management Systems - RDBMS).
Mientras la gran parte de los sistemas operacionales fueron resultados de aplicaciones basadas en antiguas estructuras de datos, los dep�sitos y sistemas de soporte de decisiones aprovecharon el RDBMS por su flexibilidad y capacidad para efectuar consultas con un �nico objetivo concreto.
Los RDBMS son muy flexibles cuando se usan con una estructura de datos normalizada. En una base de datos normalizada, las estructuras de datos son no redundantes y representan las entidades b�sicas y las relaciones descritas por los datos (por ejemplo productos, comercio y transacci�n de ventas). Pero un procesamiento anal�tico en l�nea (OLAP) t�pico de consultas que involucra varias estructuras, requiere varias operaciones de uni�n para colocar los datos juntos.
La performance de los RDBMS tradicionales es mejor para consultas basadas en claves ("Encuentre cuenta de cliente #2014") que para consultas basadas en el contenido ("Encuentre a todos los clientes con un ingreso sobre $ 10,000 que hayan comprado un autom�vil en los �ltimos seis meses").
Para el soporte de dep�sitos a gran escala y para mejorar el inter�s hacia las aplicaciones OLAP, los proveedores han a�adido nuevas caracter�sticas al RDBMS tradicional. Estas, tambi�n llamadas caracter�sticas super relacionales, incluyen el soporte para hardware de base de datos especializada, tales como la m�quina de base de datos Teradata.
Los modelos super relacionales tambi�n soportan extensiones para almacenar formatos y operaciones relacionales (ofrecidas por proveedores como REDBRICK) y diagramas de indexaci�n especializados, tales como aquellos usados por SYBASE IQ. Estas t�cnicas pueden mejorar el rendimiento para las recuperaciones basadas en el contenido, al pre juntar tablas usando �ndices o mediante el uso de listas de �ndice totalmente invertidos.
Muchas de las herramientas de acceso a los data warehouses explotan la naturaleza multidimensional del data warehouse. Por ejemplo, los analistas de marketing necesitan buscar en los vol�menes de ventas por producto, por mercado, por per�odo de tiempo, por promociones y niveles anunciados y por combinaciones de estos diferentes aspectos.
La estructura de los datos en una base de datos relacional tradicional, facilita consultas y an�lisis a lo largo de dimensiones diferentes que han llegado a ser comunes. Estos esquemas podr�an usar tablas m�ltiples e indicadores para simular una estructura multidimensional. Algunos productos DBMS, tales como ESSBASE y GENTIUM, implementan t�cnicas de almacenamiento y operadores que soportan estructuras de datos multidimensionales.
Mientras las bases de datos multidimensionales (MultiDimensional Databases - MDDBs) ayudan directamente a manipular los objetos de datos multidimensionales (por ejemplo, la rotaci�n f�cil de los datos para verlos entre dimensiones diferentes, o las operaciones de drill down que sucesivamente exponen los niveles de datos m�s detallados), se debe identificar estas dimensiones cuando se construya la estructura de la base de datos. As�, agregar una nueva dimensi�n o cambiar las vistas deseadas, puede ser engorroso y costoso. Algunos MDDBS requieren un recargue completo de la base de datos cuando ocurre una reestructuraci�n.
�Nuevas Dimensiones
Una limitaci�n de un RDBMS y un MDDB, es la carencia de soporte para tipos de datos no tradicionales como im�genes, documentos y clips de v�deo / audio. Si usted necesita estos tipos de objetos en su data warehouse, busque un DBMS relacional - objeto (Ejemplo: ILLUSTRA de INFORMIX).
Por su enfoque en los valores de datos codificados, la mayor parte de los sistemas de base de datos pueden acomodar estos tipos de datos, s�lo con extensiones basadas en cierta referencias, tales como indicadores de archivos que contienen los objetos. Muchos RDBMS almacenan los datos complejos como objetos grandes binarios (Binary Large Objects - BLOBs). En este formato, los objetos no pueden ser indexados, clasificados, o buscados por el servidor.
Los DBMS relacional - objeto, de otro lado, almacenan los datos complejos como objetos nativos y pueden soportar las grandes estructuras de datos encontradas en un ambiente orientado a objetos. Estos sistemas de base de datos naturalmente acomodan no s�lo tipos de datos especiales sino tambi�n los m�todos de procesamiento que son �nicos para cada uno de ellos.
Pero una desventaja del enfoque relacional - objeto, es que la encapsulaci�n de los datos dentro de los tipos especiales de datos (una serie de precios de stock a trav�s del tiempo en cada registro de una tabla de stock, por ejemplo), requiere de operadores especializados para que hagan b�squedas simples previamente (por ejemplo, "Encontrar todas las existencias que han mostrado una disminuci�n en el precio de Abril a Mayo 1996").
La selecci�n del DBMS est� tambi�n sujeta al servidor de hardware que se usa. Algunos RDBMS, como el DB2 Paralelo, INFORMIX XPS y el ORACLE Paralelo, ofrecen versiones que soportan operaciones paralelas. El software paralelo divide consultas, uniones a trav�s de procesadores m�ltiples y corre estas operaciones simult�neamente para mejorar la performance.
Se requiere el paralelismo para el mejor desempe�o en los servidores MPP grandes y SMP agrupados. No es a�n una opci�n con MDDBS o DBMS relacional - objeto.
En la tabla "C�mo comparar DBMS" se resume los pro y los contra de los diferentes tipos de DBMS para operaciones de data warehouse.
La tabla "Matriz de Decisi�n del Data Warehouse" contiene algunos ejemplos de c�mo afectan estos criterios de decisi�n en la elecci�n de una arquitectura de servidor/ data warehouse.
| Caracter�sticas / Funci�n | Relacional | Super Relacional | Multidimensional (L�gico) | Multidimensional (F�sico) | Objeto Relacional |
|---|---|---|---|---|---|
| Estructuras Normalizadas | � | � | � | � | � |
| Tipos de datos abstractos | � | � | � | � | � |
| Paralelismo | � | � | � | � | � |
| Estructuras Multidimensionales | � | � | � | � | � |
| Drill-Down | � | � | � | � | � |
| Rotaci�n | � | � | � | � | � |
| Operaciones dependientes de datos | � | � | � | � | � |
| Para estos ambientes... | � |
� |
Elija... | � |
� |
||
|---|---|---|---|---|---|---|---|
| Requerimientos comerciales | Usuarios | Soporte de Sistemas | Arquitectura | Servidor | DBMS | ||
|
Peque�a - ubicaci�n �nica | Local m�nimo - central promedio | Consolidado - paquete | Procesador �nico o SMP | MDDB | ||
|
Grandes Analistas en una sola ubicaci�n; usuarios inform�ticos dispersos | Local m�nimo - central promedio | Seccionado - detalle en central - resumen en local | Grupos de SMP para central; SP o SMP para local | RDBMS para central - MDDB para local | ||
|
Grande; geogr�ficamente disperso | Central fuerte | Centralizado | Grupos de SMP | Objeto-relacional- soporte Web | ||
|
Peque�a - pocas ubicaciones | Central fuerte | Centralizado | MPP | RDBMS con soporte paralelo |
�Combinacion de la Arquitectura con el Sistema de Gestion de Bases de Datos
Para seleccionar la combinaci�n correcta de la arquitectura del servidor y el DBMS, primero es necesario comprender los requerimientos comerciales de su compa��a, su poblaci�n de usuarios y las habilidades del personal de soporte.
Las implementaciones de los data warehouses var�an apreciablemente de acuerdo al �rea. Algunos son dise�ados para soportar las necesidades de an�lisis espec�fico para un solo departamento o �rea funcional de una organizaci�n, tales como finanzas, ventas o marketing. Las otras implementaciones re�nen datos a trav�s de toda la empresa para soportar una variedad de grupos de usuarios y funciones. Por regla general, a mayor �rea del dep�sito, se requiere mayor potencia y funcionalidad del servidor y el DBMS.
Los modelos de uso de los data warehouses son tambi�n un factor. Las consultas y vistas de reportes preestructuradas frecuentemente satisfacen a los usuarios inform�ticos, mientras que hay menos demandas sobre el DBMS y la potencia de procesamiento del servidor. El an�lisis complejo, que es t�pico de los ambientes de decisi�n - soporte, requiere m�s poder y flexibilidad de todos los componentes del servidor. Las b�squedas masivas de grandes data warehouses favorecen el paralelismo en el DBMS y el servidor.
Los ambientes din�micos, con sus requerimientos siempre cambiantes, se adaptan mejor a una arquitectura de datos simple, f�cilmente cambiable (por ejemplo, una estructura relacional altamente normalizada), antes que una estructura intrincada que requiere una reconstrucci�n despu�s de cada cambio (por ejemplo, una estructura multidimensional).
El valor de la data fresca requerida indica cu�n importante es para el data warehouse renovar y cambiar los datos. Los grandes vol�menes de datos que se refrescan a intervalos frecuentes, favorecen una arquitectura f�sicamente centralizada para soportar una captura de datos eficiente y minimizar el tiempo de transporte de los datos.
Un perfil de usuario deber�a identificar qui�nes son los usuarios de su data warehouse, d�nde se ubican y cu�ntos necesita soportar. La informaci�n sobre c�mo cada grupo espera usar los data warehouses, ayudar� a analizar los diversos estilos de uso.
Conocer la ubicaci�n f�sica de sus usuarios ayudar� a determinar c�mo y a qu� �rea necesita distribuir el data warehouse. Una arquitectura por niveles podr�a usar servidores en el lugar de las redes de �rea local. O puede necesitar un enfoque centralizado para soportar a los trabajadores que se movilizan y que trabajan en el dep�sito desde sus laptops.
El n�mero total de usuarios y sus modelos de conexi�n determinan el tama�o de sus servidores de dep�sito. Los tama�os de memoria y los canales de I/O deben soportar el n�mero previsto de usuarios concurrentes bajo condiciones normales, as� como tambi�n en las horas punta de su organizaci�n.
Finalmente, se debe factorizar la sofisticaci�n del personal de soporte. Los recursos de los sistemas de informaci�n (Information System - IS) que est�n disponibles dentro de su organizaci�n, pueden limitar la complejidad o sofisticaci�n de la arquitectura del servidor. Sin el personal especializado interno o consultores externos, es dif�cil de crear y mantener satisfactoriamente una arquitectura que requiere paralelismo en la plataforma del servidor (MPP o SMP agrupado, por ejemplo).
�Planes de Expansion
Como su dep�sito evoluciona y los datos que contiene llegan a ser m�s accesible, los empleados externos al dep�sito podr�an descubrir tambi�n el valor de sus datos. Al enlazar su data warehouse a otros sistemas (tanto internos como externos a la organizaci�n), se puede compartir informaci�n con otras entidades comerciales con poco o sin desarrollo. Los mensajes de correo electr�nico, servidores WEB y conexiones Intranet/Internet, pueden entregar listas por niveles a sus proveedores o seg�n su condici�n, a sus socios de negocio.
Como los data warehouses contin�an creciendo en sofisticaci�n y uso, los datos acumulados dentro de una empresa llegar�n a ser m�s organizados, m�s interconectados, m�s accesibles y, en general, m�s disponibles a m�s empleados.
El resultado ser� la obtenci�n de mejores decisiones en el negocio, m�s oportunidades y m�s claridad de trabajo.
�Confiabilidad de los Datos
La data "sucia" es peligrosa. Las herramientas de limpieza especializadas y las formas de programar de los clientes proporcionan redes de seguridad.
No importa c�mo est� dise�ado un programa o cu�n h�bilmente se use. Si se alimenta mala informaci�n, se obtendr� resultados incorrectos o falsos. Desafortunadamente, los datos que se usan satisfactoriamente en las aplicaciones de l�nea comercial operacionales pueden ser basura en lo que concierne a la aplicaci�n data warehousing.
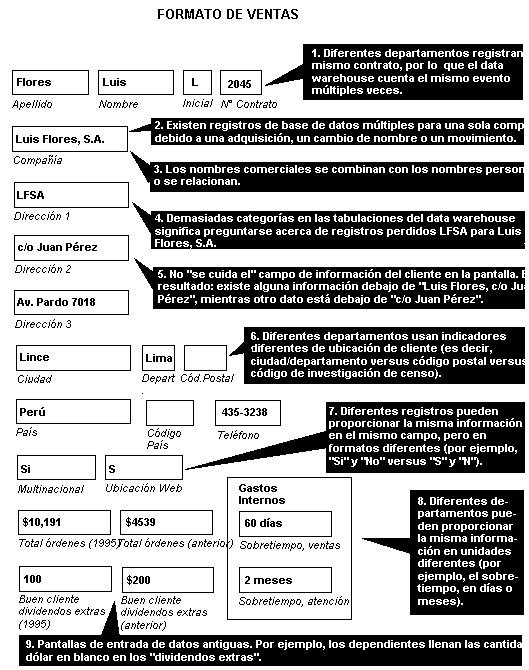
Los datos "sucios" pueden presentarse al ingresar informaci�n en una entrada de datos (por ejemplo, "Sistemas S. A." en lugar de "Sistemas S. A.") o de otras causas. Cualquiera que sea, la data sucia da�a la credibilidad de la implementaci�n del dep�sito completo. A continuaci�n, en la Figura N� 19 se muestra un ejemplo de formato de ventas en el que se pueden presentar errores.
Afortunadamente, las herramientas de limpieza de datos pueden ser de gran ayuda. En algunos casos, puede crearse un programa de limpieza efectivo. En el caso de bases de datos grandes, imprecisas e inconsistentes, el uso de las herramientas comerciales puede ser casi obligatorio.
Decidir qu� herramienta usar es importante y no solamente para la integridad de los datos. Si se equivoca, se podr�a malgastar semanas en recursos de programaci�n o cientos de miles de d�lares en costos de herramientas.
La limpieza de una data "sucia" es un proceso multifac�tico y complejo. Los pasos a seguir son los siguientes:
- Analizar sus datos corporativos para descubrir inexactitudes, anomal�as y otros problemas.
- Transformar los datos para asegurar que sean precisos y coherentes.
- Asegurar la integridad referencial, que es la capacidad del data warehouse, para identificar correctamente al instante cada objeto del negocio, tales como un producto, un cliente o un empleado.
- Validar los datos que usa la aplicaci�n del data warehouse